


Sumário
2. Copiar arquivos para dentro e fora do cluster
3. Comandos básicos para serem usados no cluster
3.1 Diretórios
3.2 Arquivos
3.3 Edição de arquivos
Manual de uso do Cluster
1. Login no cluster Gauss
O acesso ao cluster Gauss é feito por meio de usuário e senha, se você não possui entre no link https://forms.gle/E2UZfiJFvhzMGBMH6 e solicite sua conta no cluster. Caso não receba resposta, entre em contato com o suporte da Gauss (gausshpc@usp.br) para fazer o cadastro. Tendo as informações de login e senha, entre no terminal do seu computador, use o comando abaixo para entrar na máquina ingauss (que é um computador de entrada configurado para proteger a Gauss contratentativa de invasão), substituindo usuario pelo seu nome de usuário (username). Saiba que o símbolo $ representa o prompt do seu terminal e não faz parte do comando.
$ ssh usuario@ingauss.if.usp.br
Se estiver no windows e retornar um erro afirmando que ssh não é reconhecido, você precisa habilitar o ssh, siga as instruções do link https://pureinfotech.com/install-openssh-client-windows-10/. Sendo seu primeiro acesso a Gauss, a mensagem mostrada na figura 1 aparecerá ou uma parecida.
![]()
Figura 1: Mensagem de autenticação ssh.
Responda com “yes” e após aparecer o prompt de comando faça o acesso a Gauss usando o comando ssh novamente:
$ ssh usuario@gauss.if.usp.br
responda a pergunta com "yes"novamente, digite a senha novamente e o seu terminal estará parecido com a figura 2, com isso você está logado na Gauss. Repare que a senha não aparece ao seu digitada, nem qualquer outro sinal.
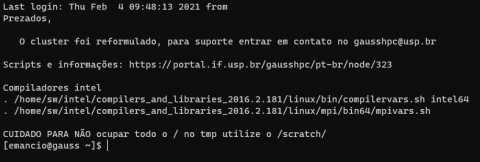
Figura 2: Terminal após acesso na Gauss.
Se tiver alguma dificuldade com o login entre em contato com o suporte.
2. Copiar arquivos para dentro e fora do cluster
Para copiar arquivos do seu computador local para a Gauss, ou vice-versa, use o comando scp. Mas antes é necessário criar um túnel entre o seu computador (localhost) para o cluster Gauss, passando pela máquina Ingauss. No terminal do seu computador use o comando ssh para criar o túnel entre a porta 50022 do seu computador e a porta 22 da Gauss:
$ ssh usuario@ingauss.if.usp.br -NL 50022:gauss.if.usp.br:22
e digite a sua senha. Assim, o túnel está criado e ficará aberto sem retornar o seu cursor. Então abra um outro terminal no seu computador e use o comando scp para copiar os arquivos para a Gauss:
$ scp -P 50022 arquivo usuario@localhost:diretoria_na_Gauss/.
ou para copiar os arquivos da Gauss:
$ scp -P 50022 usuario@localhost:diretorio_na_Gauss/arquivo .
Lembre-se de colocar o path completo dos arquivos que for copiar da Gauss para o seu computador. Além disso, é possível copiar pastas inteiras com o comando scp:
$ scp -P 50022 -r diretorio usuario@localhost:diretorio_na_Gauss/arquivo .
Ademais, o comando scp vai sempre pedir a sua senha de acesso da Gauss.
_____________________________________________________________
Exemplo: Para o usuário da Gauss joao copiar o arquivo script.csh e o diretório mol-1 do seu computador para a Gauss no diretório /home/users/joao/simulacao, é necessário no computador local: (i) abrir um terminal, dar o comando ssh para criar o túnel
$ ssh joao@ingauss.if.usp.br -NL 50022:gauss.if.usp.br:22
e digitar a senha; (ii) abrir outro terminal, vá para o diretório com o arquivo e diretório a ser copiado, dar o comando scp para copiar o arquivo
$ scp -P 50022 script.csh joao@localhost:/home/users/joao/simulacao/.
e digitar a senha; (iii) dar novamente o comando scp para copiar o diretório
$ scp -P 50022 -r mol-1 joao@localhost:/home/users/joao/simulacao/.
______________________________________________________________________
Mais informações sobre o comando:
3. Comandos básicos para serem usados no cluster
3.1. Diretório
Assim que entrar na Gauss, você estará na sua pasta ou diretório home do servidor principal (head-node) que tem 2Tb de disponibilidade para todos os usuário, no diretório ”/home/users/usuario”. Para verificar o diretório em que você está, use o comando:
$ pwd
Também existe uma outra pasta para armazenar os arquivos no diretório ”/home1/users/usuario” que tem 51Tb de disponibilidade para todos os usuário. Então após executar alguns programas copie seus arquivos/pastas para seu diretório no disco /home1. Assim, não corre o risco de lotar o disco /home e bloquear o head-node. Sempre que analizar seus dados comprima suas pass para econimizar o espaço em disco.
Como os programas geram muitos arquivos, é interessante que você crie pastas, para manter tudo organizado, a partir do comando:
$ mkdir nome_da_pasta
Tendo a nova pasta, para entrar nela use:
$ cd nome_da_pasta
Para retornar a pasta anterior, use:
$ cd ..
O comando cd pode ser utilizado para ir a qualquer pasta desde que você tenha o caminho (path) dela. Por exemplo, se você estiver na sua pasta na home, e queira ir para a pasta ”/home/users/usuario/Dice/Sim/Resultados”, basta usar:
$ cd /home/users/usuario/Dice/Sim/Resultados
ou
$ cd ∼/Dice/Sim/Resultados
Perceba que ∼ representa a sua pasta na home, logo, para retornar para ela de qualquer outra pasta, basta usar:
$ cd ∼
Assim como ∼ representa sua pasta na home, ”.” representa a sua pasta atual e ”..” a pasta na qual ”.” está contida. Mais informações sobre os comandos:
- cd no link https://linuxize.com/post/linux-cd-command/
- mkdir no link https://linuxize.com/post/how-to-create-directories-in-linux-with-the-mkdir-command/
- pwd no link https://linuxize.com/post/current-working-directory/
3.2. Arquivos
Para listar os arquivos em um diretório use:
$ ls
O comando mv é usado para mover os arquivos:
$ mv nome_do_arquivo pasta_de_destino
Além disso, ele pode ser usado para renomear um arquivo:
$ mv nome_atual novo_nome
Para copiar algum arquivo use:
$ cp nome_do_arquivo pasta_de_destino
ou
$ cp nome_do_arquivo nome_do_arquivo_copiado
Por exemplo:
$ cp text.txt text_backup.txt
Criará o text backup.txt que é uma cópia do arquivo text.txt no mesmo diretório. Já:
$ cp text.txt /home
Criará uma cópia de text.txt na pasta /home. Para ler os arquivos de texto diretamente do terminal use o comando more:
$ more nome_do_arquivo
Ele inicialmente apresentará algumas linhas do arquivo, mas ao usar a tecla Enter ele mostrará mais linhas. Caso você queira parar de ler o arquivo precisa cancelar o comando com Ctrl + C (Win/Liux) ou Cmd + C (Mac). Caso você queira somente uma quantidade de linhas do arquivo use:
$ head -n[numero_de_linhas] nome_do_arquivo
Por exemplo:
$ head -n2 resultados.out
Irá retornar as duas primeiras linhas do arquivo resultados.out. Se você quiser as linhas do final substitua head por tail. Se você rodar a opção -n[numero de linhas], os comandos head e tail mostrarão 10 linhas como padrão.
Se você precisar verificar se há alguma palavra específica em um arquivo use:
$ grep palavra arquivo
Mais informações sobre os comandos:
- ls no link https://linuxize.com/post/how-to-list-files-in-linux-using-the-ls-command/
- mv no link https://linuxize.com/post/how-to-move-files-in-linux-with-mv-command/
- cp no link https://linuxize.com/post/cp-command-in-linux/
- more no link https://www.geeksforgeeks.org/more-command-in-linux-with-examples/
- head no link https://www.geeksforgeeks.org/head-command-linux-examples/
- tail no link https://www.hostinger.com.br/tutoriais/comando-tail-linux/
- grep no link https://www.hostinger.com.br/tutoriais/comando-grep-linux/
3.3. Edição de arquivos
É sugerido que toda edição de arquivos seja feita no seu micro local e depois copiar os arquivo para Gauss. Mas se for preciso editar arquivos que já estão na Gauss use algum editor de terminal, como por exemplo o vim. Por ser um comando mais complexo e fugir do escopo desse guia, recomendo a leitura desses tutoriais:
4. Fila de jobs
A Gauss possui 5 filas – biomol, inct, schwinger, biomolgpu, atmol – possivelmente você não terá acesso a todas, em dúvida contate o suporte. Para rodar os programas, a Gauss usa um sistema de jobs onde você pede uma quantidade de processadores e de memória e o job entra em uma das filas, se houverem processadores e memória o job começa a rodar, se não, fica na espera até haver.
Para saber como estão os jobs que estão rodando na Gauss use:
$ qstat
Que retornará como mostrado na figura 3.
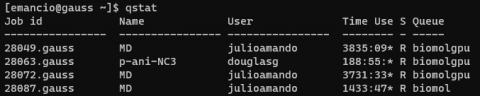
Figura 3: Resultado do comando qstat.
O Job id é o número associado ao job, o Name é uma variável que você define quando submete o job, User é o usuário que submeteu, Time é o tempo que está rodando no formato hhhh:mm, S é a situação que o job está: R significa running (rodando), Q queueing (em espera) e E elapsed (terminou), e Queue é a fila que o job está.
A Gauss é um cluster de vários computadores, chamamos os computadores individuais de nodes, a lista dos nodes disponíveis esá no link https://portal.if.usp.br/gausshpc/node. Os jobs rodam em único node e para saber em qual o job está rodando use:
$ qstat -n
O node aparecerá junto com o Job id. Além disso, para verificar apenas os seus jobs, pode usar:
$ qstat -na -u usuario
Mais informações sobre o comando qstat podem ser encontradas nesse link http://docs.adaptivecomputing.com/torque/4-1-3/Content/topics/commands/qstat.htm. Como o job roda no node, normalmente os arquivos relativos ao job não estão acesíveis diretamente, para acessá-los você precisa entrar no node, usando:
$ ssh nome_do_node
Por exemplo, para acessar o node12 use:
$ ssh node12
Muitas vezes é interessante saber se algum node está livre ou quantos processadores ele tem disponível, isso pode ser obtido utilizando:
$ pbsnodes nome_do_node
Ele retornará informações de todos os nodes, por exemplo:
$ pbsnodes node22
Resultará nas informações mostradas na figura 4, vemos que o node22 possui 32 processadores sendo que 26 estão em uso, além disso que ele tem pouco mais de 60GB de memória e que 8GB estão em uso. Com isso, sabemos que podemos submeter um job diretamente ao node22 com 6 processadores.
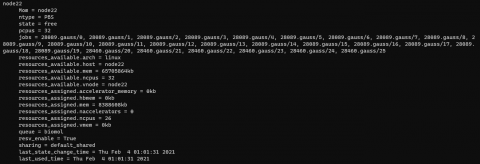
Figura 4: Informações do node22.
Podemos receber essas informações de todos os nodes com:
$ pbsnodes -a
Mais informações sobre os comandos:
5. Submissão de jobs
A submissão de um job na Gauss e feita através de um arquivo script em bash e usando o comando qsub, como mostrado a seguir:
$ qsub script.sh
Exemplos de script pode ser encontrados no link https://portal.if.usp.br/gausshpc/script. Como informado antes, o job usualmente roda no node, mais especificamente na pasta ”/scratch/local/jobid.gauss”, por exemplo o job 29574 está na pasta ”/scratch/local/29574.gauss” do node. Vale ressaltar que isso nem sempre é verdadeiro dado que depende de um conjunto de comandos no script. Se estes comandos não estiverem no script então os arquivos são gerados no seu home e poderão ser acessíveis sem precisar acessar o node, mas isso influencia no tempo de execução do job (que ficará mais lento) já que os dados precisão ser gravados no disco do servidor (heard node). Logo, garanta que os arquivos sejam acessíveis apenas no node. Ao final do job, é interessante acessar o node que o job foi executado e verificar se os dados do scratch foram realmente apagados, para garantir a operação contínua dos jobs.
Além disso, para remover um job use:
$ qdel job_id
Por exemplo, para deletar o job com id 29574 se utiliza:
$ qdel 29574
Quando você usar o qstat ele adiciona ao número ”.gauss” ao número, lembre-se que não precisa adicioná-lo para o comando qdel.
Todos os scripts possuem uma parte de configuração com o seguinte formato:
#!/bin/bash
#PBS -S /bin/bash
#PBS -l nodes=1:ppn=12
#PBS -l walltime =300:00:00
#PBS -l mem=16GB
#PBS -N nome_do_job
#PBS -q biomol
Na qual podemos especificar o node substituindo nodes=1 por nodes=nome do node. Se quiséssemos rodar no node22, usaríamos nodes=node22. Não é necessário especificar o node para a execução, pois sem especificar o seu job vai entrar no primeiro node que ficar livre e atender sua especificação de processadores e memória livre. Neste caso a linha ficara assim:
#PBS -l ppn=12
Já ppn é relativo a quantidade de processadores, walltime é o tempo máximo que o job vai rodar, se esse tempo for atingido tudo que estiver rodando relativo ao job será parado e finalizado, nesse caso os programas normalmente possuem um comando de continuação; mem é a quantidade de memória requerida. A penúltima linha define o nome do job e a última a fila que o job será submetido, se ele for posto numa fila que você não tem autorização, ele não irá rodar.
Importante: Se você deletar um job ou se acontecer algum erro que impeça a finalização normal do job, garanta que a pasta de execução no node com os arquivos seja apagada para não lotar os discos locais dos notes e impedir que outros usuários executem.
Importante: Se você submeter um job e ele ficar com status E (elapsed), avise o suporte. Enquanto isso verifique outro node disponível e altere o script de submissão especificando o node, para que ele vá para outro node quando for submetido, uma vez que se você cancelar o job e submetê-lo de novo, provavelmente ele irá para o mesmo node e apresentará o mesmo problema.
